knowledge-base
eBPF
简介
eBPF (extended Berkeley Packet Filter) 是一项革命性的技术,起源于 Linux 内核,它可以在特权上下文中(如操作系统内核)运行沙盒程序。它用于安全有效地扩展内核的功能,而无需通过更改内核源代码或加载内核模块的方式来实现。
从历史上看,由于内核具有监督和控制整个系统的特权,操作系统一直是实现可观测性、安全性和网络功能的理想场所。同时,由于操作系统内核的核心地位和对稳定性和安全性的高要求,操作系统内核很难快速迭代发展。因此在传统意义上,与在操作系统本身之外实现的功能相比,操作系统级别的创新速度要慢一些。
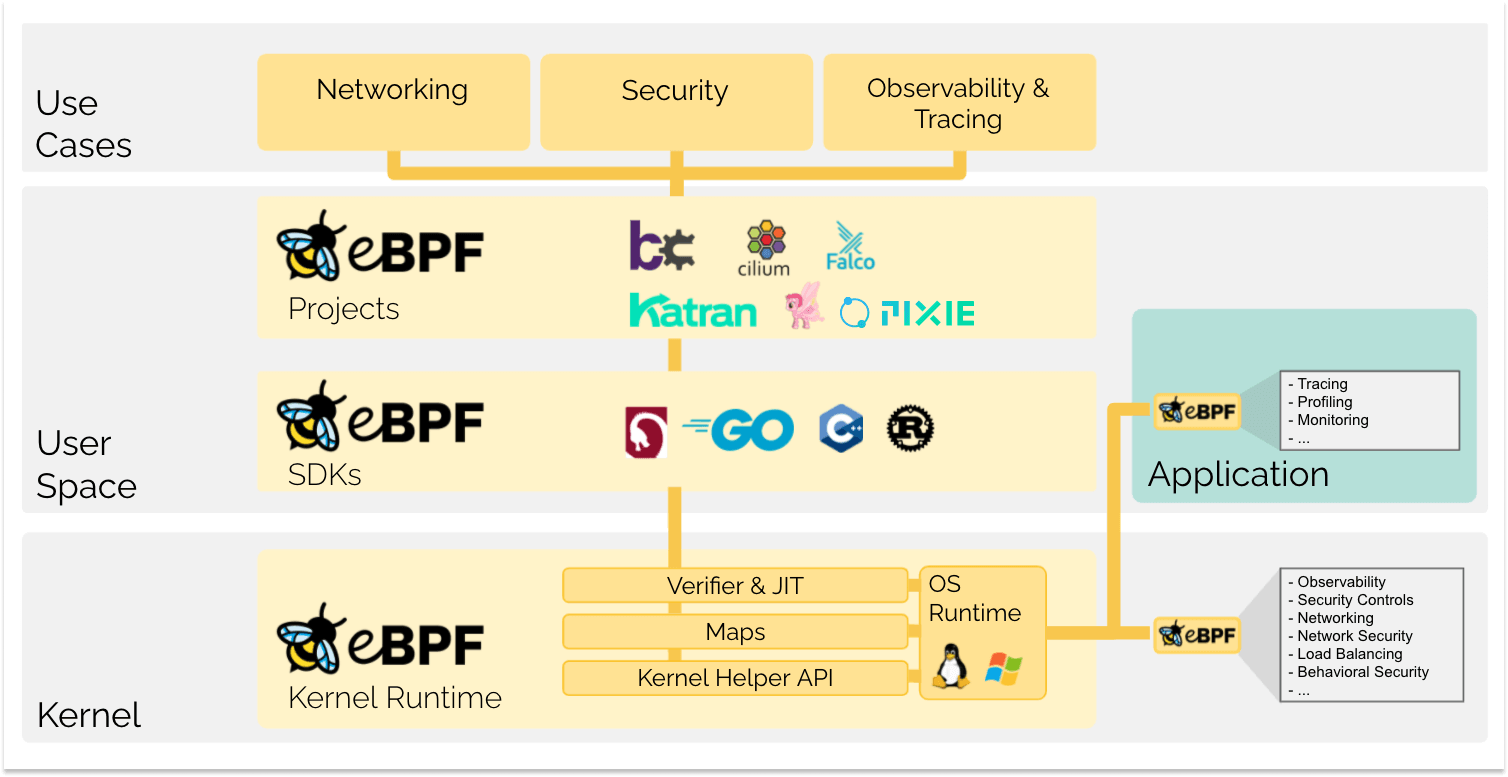
eBPF 从根本上改变了这个方式。通过允许在操作系统中运行沙盒程序的方式,应用程序开发人员可以运行 eBPF 程序,以便在运行时向操作系统添加额外的功能。然后在 JIT 编译器和验证引擎的帮助下,操作系统确保它像本地编译的程序一样具备安全性和执行效率。这引发了一股基于 eBPF 的项目热潮,它们涵盖了广泛的用例,包括下一代网络实现、可观测性和安全功能等领域。
如今,eBPF 被广泛用于驱动各种用例:在现代数据中心和云原生环境中提供高性能网络和负载均衡,以低开销提取细粒度的安全可观测性数据,帮助应用程序开发人员跟踪应用程序,为性能故障排查、预防性的安全策略执行(包括应用层和容器运行时)提供洞察,等等。可能性是无限的,eBPF 开启的创新才刚刚开始。
钩子
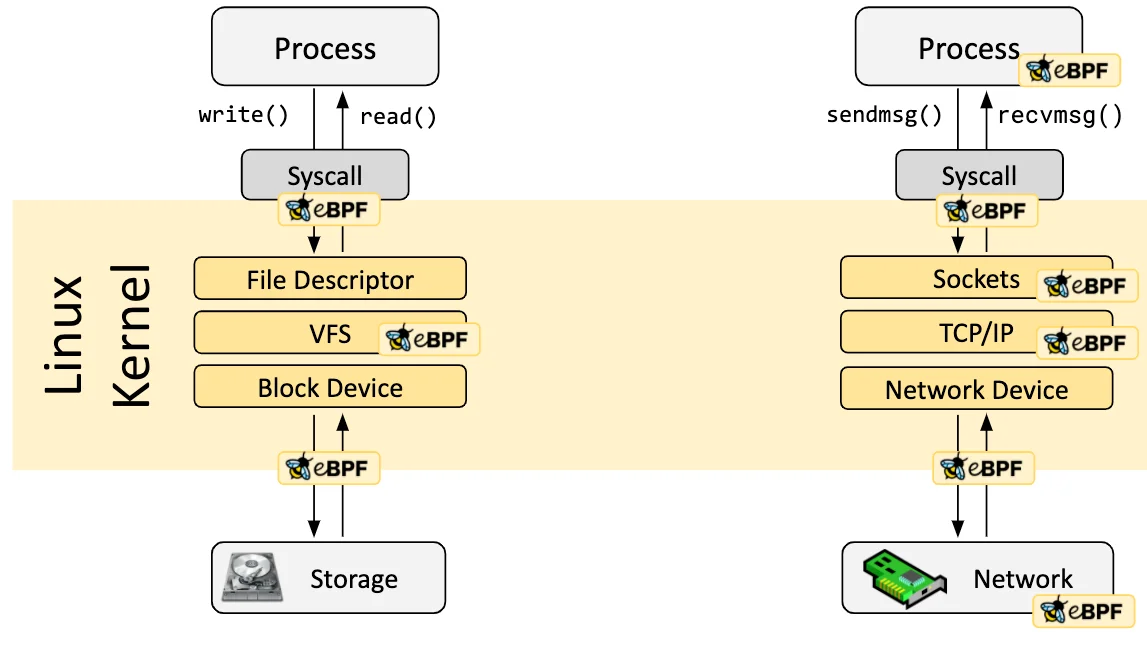
eBPF 程序是事件驱动的,当内核或应用程序通过某个钩子点时运行。预定义的钩子包括系统调用、函数入口/退出、内核跟踪点、网络事件等。
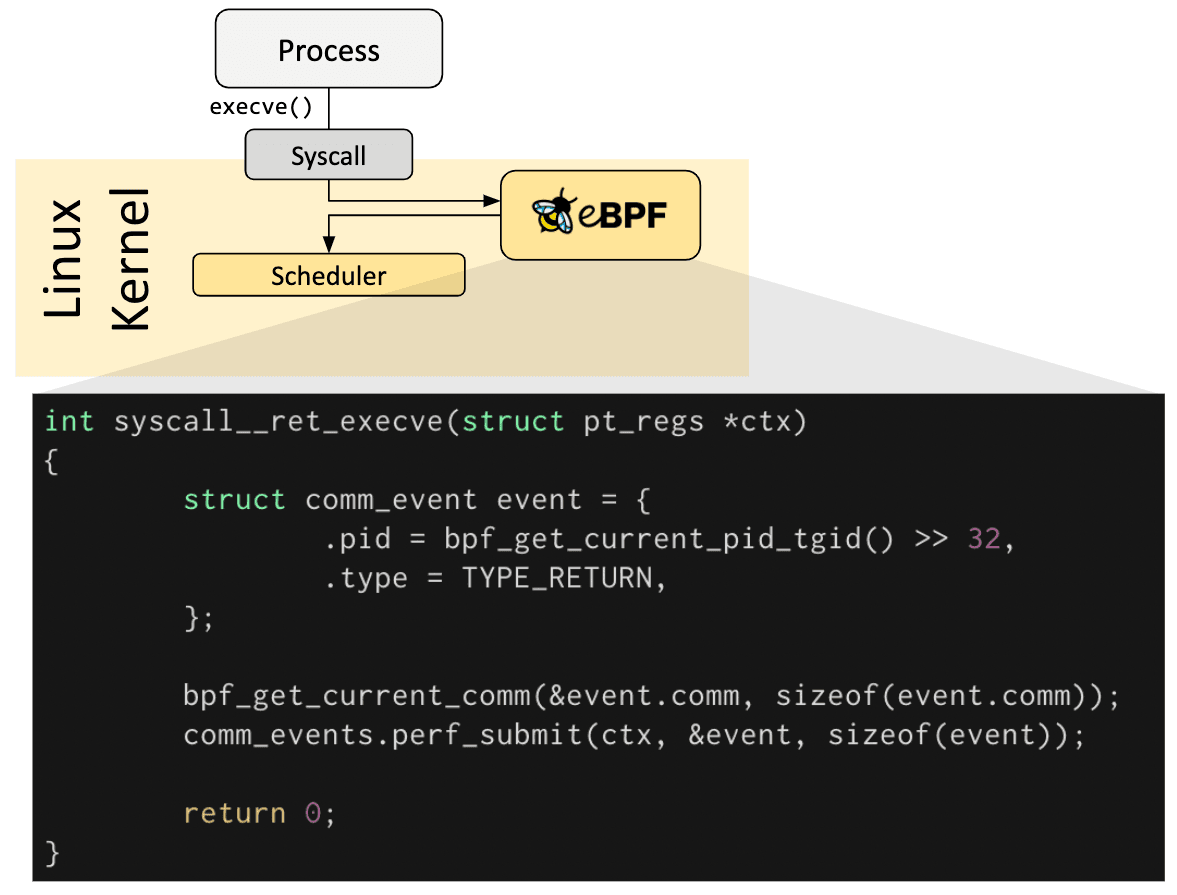
如果预定义的钩子不能满足特定需求,则可以创建内核探针(kprobe)或用户探针(uprobe),以便在内核或用户应用程序的几乎任何位置附加 eBPF 程序。
编写程序
在很多情况下,eBPF 不是直接使用,而是通过像 Cilium、bcc 或 bpftrace 这样的项目间接使用,这些项目提供了 eBPF 之上的抽象,不需要直接编写程序,而是提供了指定基于意图的来定义实现的能力,然后用 eBPF 实现。

如果不存在更高层次的抽象,则需要直接编写程序。Linux 内核期望 eBPF 程序以字节码的形式加载。虽然直接编写字节码当然是可能的,但更常见的开发实践是利用像 LLVM 这样的编译器套件将伪 c 代码编译成 eBPF 字节码。
安全性
由于 eBPF 允许我们在内核中运行任意代码,需要有一种机制来确保它的安全运行,不会使用户的机器崩溃,也不会损害他们的数据。这个机制就是 eBPF 验证器。
验证器对 eBPF 程序进行分析,以确保无论输入什么,它都会在一定数量的指令内安全地终止。
云原生领域
屏弃 SideCar 模式,将eBPF 加载到内核,跟随事件触发。