knowledge-base
我的知识库 / Kubernetes / Prometheus
Prometheus
Intro
是一个面向云原生应用程序的开源的监控&报警工具。
- 开源:继Kubernetes之后的第二个CNCF开源项目,Go语言开发
- 监控:通过HTTP服务定时从配置的目标收集指标数据,识别数据展示规则,展示监控系统和服务指标数据
- 报警:监控到的指标数据达到某一设定好的条件时,触发报警机制
- 时间序列数据库: 时间序列是由唯一的指标名称(Metrics)和一组标签(key=value)的形式组成
- PromeQL:基于Prometheus时间序列数据库的一个灵活的查询语言
Prometheus的监控对象
-
资源监控:
服务器的资源使用情况,在Kubernetes集群中,则可以做到对Kubernetes Node、 Deployment 、Pod的资源利用以及apiserver,controller-manager,etcd等组件的监控。
-
应用监控:
业务应用暴露端口供Prometheus调用实现监测,比如实时的用户在线人数,数据库的当前连接数等。
Prometheus优势
- 支持机器资源和动态配置的应用监控;
- 多维数据收集和查询;
- 服务独立,少依赖。
Prometheus组件
- Prometheus Server:采集监控数据,存储时序指标,提供数据查询;
- Prometheus Client SDK:对接开发工具包,提供自定义的指标数据等;
- Push Gateway:推送指标数据的网关组件;
- Third-part Exporter:外部指标采集系统,暴露接口供Prometheus采集;
- AlertManager:指标数据的分析告警管理器;
Architecture overview
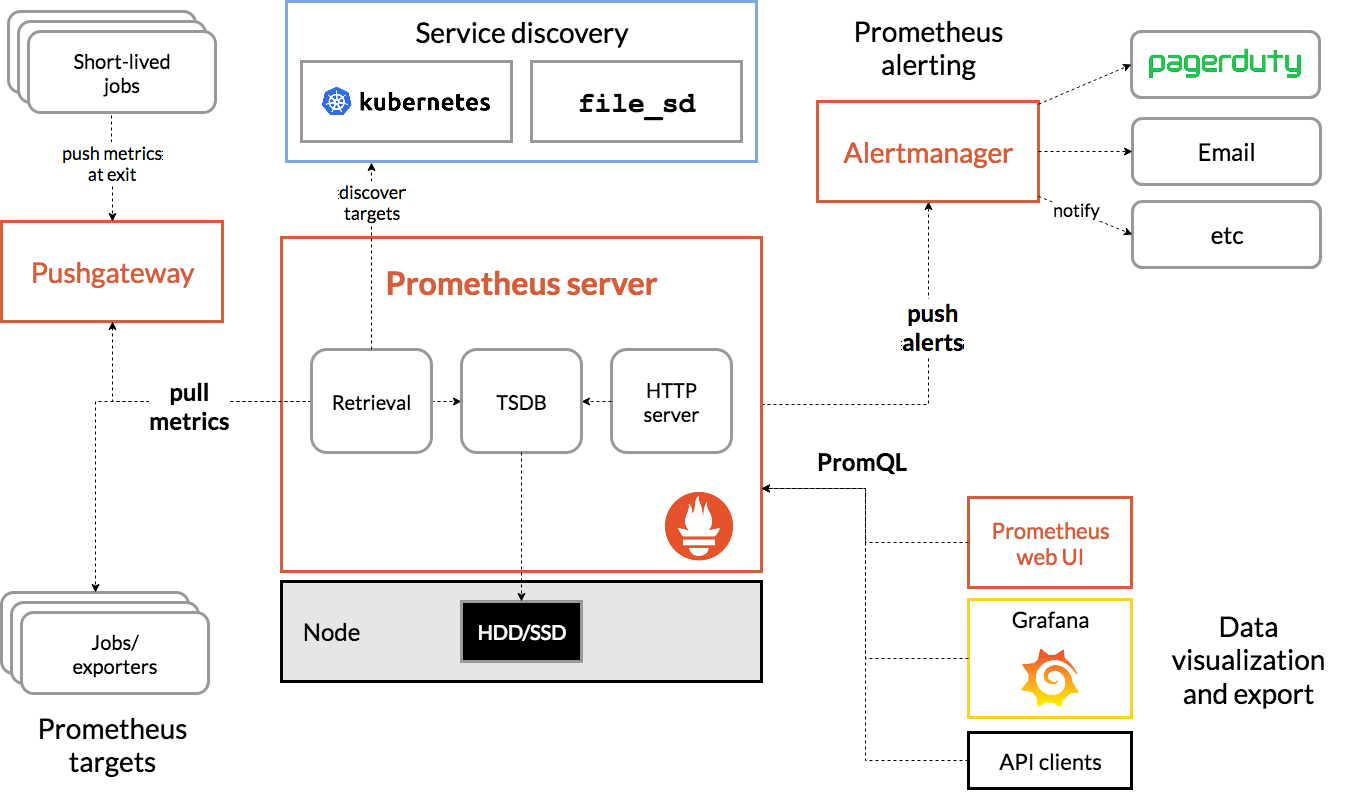
上图来源于官网:
- 处理流程:
- 配置资源目标或应用抓取;
- 抓取资源或应用指标数据;
- 制定报警规则,推送报警;
- 灵活查询语言,结合Grafana展示
Installation & Start Up
1. 以服务进程运行Prometheus
在ubuntu系统上安装Prometheus,一般有两种方式
-
第一种,安装命令如下:
wget https://github.com/prometheus/prometheus/releases/download/v2.13.1/prometheus-2.13.1.linux-amd64.tar.gz tar xvfz prometheus-2.13.1.linux-amd64.tar.gz # 启动Prometheus cd prometheus-2.13.1.linux-amd64 ./prometheus # 停止Prometheus ps -ef | grep prometheus # 定位Prometheus进程的pid kill -s 9 [pid] -
第二种,安装命令如下(ubuntu系统):
wget https://s3-eu-west-1.amazonaws.com/deb.robustperception.io/41EFC99D.gpg | sudo apt-key add - sudo apt-get update -y sudo apt-get install prometheus prometheus-node-exporter prometheus-pushgateway prometheus-alertmanager -y # 启动Prometheus sudo systemctl start prometheus sudo systemctl enable prometheus sudo systemctl status prometheus
Service Proxy
默认Prometheus的访问方式是http://{ip/domain-name}:9090,而服务器一般的是不会暴露9090端口的,而是暴露80端口,其他端口以nginx代理访问。
下面的步骤便是将http://{ip/domain-name}:9090代理为http://{ip/domain-name}/prometheus
-
Step 1 配置prometheus:
-
配置–web.external-url
如果是第一种方式安装的Prometheus,则启动Prometheus的命令行需要附带–web.external-url=prometheus,完整命令如下:
./prometheus --web.external-url=prometheus如果是第二种方式安装的Prometheus,则需要在/etc/default/prometheus文件在
ARGS=""中添加参数--web.external-url=prometheus,添加完之后,文件应该是像下面这样的: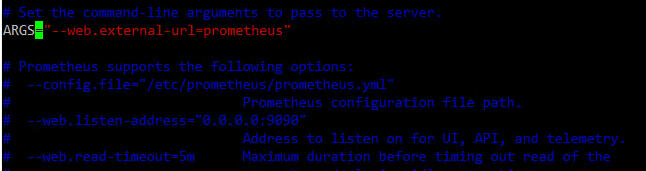
-
重启prometheus
sudo systemctl restart prometheus重启之后,http://{ip/domain-name}:9090/prometheus可以访问。
-
-
Step 2 配置nginx:
默认服务器已经安装了nginx。
-
nginx.conf文件,注释掉以下行:
#include /etc/nginx/sites-enabled/*; -
执行以下命令:
sudo vim /etc/nginx/conf.d/prometheus.conf在文件中写入以下内容:
server { location /prometheus { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://172.31.23.19:9090/prometheus; break; } } -
重启nginx
sudo systemctl restart nginx.service重启之后,http://{ip/domain-name}/prometheus可以访问。
-
停止Prometheus
sudo systemctl stop prometheus
2.Docker启动Prometheus
docker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus
3. Kubernetes运行Prometheus
ConfigMap
Prometheus的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: ns-prometheus
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
Deployment
apiVersion: app/v1
kind: Deployment
metadata:
name: prometheus
namespace: ns-prometheus
labels:
app: prometheus
spec:
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: prom/prometheus
name: prometheus
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=7d"
- "--web.enable-admin-api"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: "/prometheus"
subPath: prometheus
name: data
- mountPath: "/etc/prometheus"
name: config
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 1000m
memory: 2Gi
securityContext:
runAsUser: 0
volumes:
- name: config
configMap:
name: prometheus-config
- name: data
persistentVolumeClaim:
claimName: prometheus
PersistentVolumeClaim
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus
namespace: ns-prometheus
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: "rook-ceph-block"
ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: ns-prometheus
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-ops
Service
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: ns-prometheus
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
Apply
kubectl apply -f .
kubectl get svc -o wide -n ns-prometheus
4.官方kubernets运行Prometheus
参考:https://github.com/coreos/kube-prometheus
5.Kubernetes部署Prometheus+Grafana
- 下载相关k8s资源文件
git clone https://github.com/coreos/kube-prometheus.git
-
修改文件kube-prometheus/manifests/prometheus-prometheus.yaml,做这一步的目的是为prometheus的访问分配子路径,访问方式为http(s)://xxx/prometheus
在prometheus.spec下添加
externalUrl: prometheus
routePrefix: prometheus
-
修改文件kube-prometheus/manifests/grafana-deployment.yaml,做这一步的目的是为grafana的访问分配子路径,访问方式为:http(s)://xxx/grafana
在deployment.spec.template.spec.container[0]下添加
env:
- name: GF_SERVER_ROOT_URL
value: "http://localhost:3000/grafana"
- name: GF_SERVER_SERVE_FROM_SUB_PATH
value: "true"
- Apply k8s资源
# 可能需要运行多次以下命令,确保k8s资源都创建
kubectl create -f manifests/setup -f manifests
# !如果要删除以上创建的k8s资源,运行以下命令
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
- Ingress转发
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
spec:
rules:
- host: dp.example.tech
http:
paths:
- path: /prometheus
backend:
serviceName: prometheus-k8s
servicePort: 9090
- path: /grafana
backend:
serviceName: grafana
servicePort: 3000
- path: /alertmanager
backend:
serviceName: alertmanager-main
servicePort: 9093
- -
Configuring Prometheus
配置文件为prometheus.yml,文件格式为yaml。
Concepts
Metrics
存储
Prometheus 2.x 默认将时间序列数据库保存在本地磁盘中,同时也可以将数据保存到任意第三方的存储服务中。
本地存储
Prometheus 采用自定义的存储格式将样本数据保存在本地磁盘当中。
存储格式
Prometheus 按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中。每个块都是一个单独的目录,里面含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。其中索引文件会将指标名称和标签索引到样板数据的时间序列中。此期间如果通过 API 删除时间序列,删除记录会保存在单独的逻辑文件 tombstone 当中。
当前样本数据所在的块会被直接保存在内存中,不会持久化到磁盘中。为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))重新记录,从而恢复数据。预写日志文件保存在 wal 目录中,每个文件大小为 128MB。wal 文件包括还没有被压缩的原始数据,所以比常规的块文件大得多。一般情况下,Prometheus 会保留三个 wal 文件,但如果有些高负载服务器需要保存两个小时以上的原始数据,wal 文件的数量就会大于 3 个。
Prometheus保存块数据的目录结构如下所示:
rometheus 提供了几个参数来修改本地存储的配置,最主要的有:
启动参数
默认值
含义
--storage.tsdb.path
/data
数据存储路径
--storage.tsdb.retention.time
15d
样本数据在存储中保存的时间。超过该时间限制的数据就会被删除。
--storage.tsdb.retention.size
0
每个块的最大字节数(不包括 wal 文件)。如果超过限制,最早的样本数据会被优先删除。支持的单位有 KB, MB, GB, PB,例如:“512MB”。该参数只是试验性的,可能会在未来的版本中被移除。
--storage.tsdb.retention
该参数从 2.7 版本开始已经被弃用,使用 --storage.tsdb.retention.time 参数替代
在一般情况下,Prometheus 中存储的每一个样本大概占用1-2字节大小。如果需要对 Prometheus Server 的本地磁盘空间做容量规划时,可以通过以下公式计算:./data
|- 01BKGV7JBM69T2G1BGBGM6KB12 # 块
|- meta.json # 元数据
|- wal # 写入日志
|- 000002
|- 000001
|- 01BKGTZQ1SYQJTR4PB43C8PD98 # 块
|- meta.json #元数据
|- index # 索引文件
|- chunks # 样本数据
|- 000001
|- tombstones # 逻辑数据
|- 01BKGTZQ1HHWHV8FBJXW1Y3W0K
|- meta.json
|- wal
|-000001
最初两个小时的块最终会在后台被压缩成更长的块。
[info] 注意:
本地存储不可复制,无法构建集群,如果本地磁盘或节点出现故障,存储将无法扩展和迁移。因此我们只能把本地存储视为近期数据的短暂滑动窗口。如果你对数据持久化的要求不是很严格,可以使用本地磁盘存储多达数年的数据。
关于存储格式的详细信息,请参考 TSDB 格式
本地存储配置
rometheus 提供了几个参数来修改本地存储的配置,最主要的有:
| 启动参数 | 默认值 | 含义 |
|---|---|---|
| –storage.tsdb.path | /data | 数据存储路径 |
| –storage.tsdb.retention.time | 15d | 样本数据在存储中保存的时间。超过该时间限制的数据就会被删除。 |
| –storage.tsdb.retention.size | 0 | 每个块的最大字节数(不包括 wal 文件)。如果超过限制,最早的样本数据会被优先删除。支持的单位有 KB, MB, GB, PB,例如:“512MB”。该参数只是试验性的,可能会在未来的版本中被移除。 |
| –storage.tsdb.retention | 该参数从 2.7 版本开始已经被弃用,使用 –storage.tsdb.retention.time 参数替代 |
在一般情况下,Prometheus 中存储的每一个样本大概占用1-2字节大小。如果需要对 Prometheus Server 的本地磁盘空间做容量规划时,可以通过以下公式计算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
从上面公式中可以看出在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。因此有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。考虑到 Prometheus 会对时间序列进行压缩效率,减少时间序列的数量效果更明显。
如果你的本地存储出现故障,最好的办法是停止运行 Prometheus 并删除整个存储目录。因为 Prometheus 的本地存储不支持非 POSIX 兼容的文件系统,一旦发生损坏,将无法恢复。NFS 只有部分兼容 POSIX,大部分实现都不兼容 POSIX。
除了删除整个目录之外,你也可以尝试删除个别块目录来解决问题。删除每个块目录将会丢失大约两个小时时间窗口的样本数据。所以,Prometheus 的本地存储并不能实现长期的持久化存储。:
如果同时指定了样本数据在存储中保存的时间和大小,则哪一个参数的限制先触发,就执行哪个参数的策略。
远程存储
Prometheus 的本地存储无法持久化数据,无法灵活扩展。为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在 Promthues 中称为 Remote Storage。
Prometheus 可以通过两种方式来集成远程存储。
Remote Write
用户可以在 Prometheus 配置文件中指定 Remote Write(远程写)的 URL 地址,一旦设置了该配置项,Prometheus 将采集到的样本数据通过 HTTP 的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。

Remote Read
如下图所示,Promthues 的 Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues 将向 remote_read 中配置的 URL 发起查询请求(matchers,ranges),Adaptor 根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为 Promthues 的原始样本数据返回给 Prometheus Server。
当获取到样本数据后,Promthues 在本地使用 PromQL 对样本数据进行二次处理。
[info] 注意:
启用远程读设置后,Prometheus 仅从远程存储读取一组时序样本数据(根据标签选择器和时间范围),对于规则文件的处理,以及 Metadata API 的处理都只基于 Prometheus 本地存储完成。这也就意味着远程读在扩展性上有一定的限制,因为所有的样本数据都要首先加载到 Prometheus Server,然后再进行处理。所以 Prometheus 暂时不支持完全分布式处理。

远程读和远程写协议都使用了基于 HTTP 的 snappy 压缩协议的缓冲区编码,目前还不稳定,在以后的版本中可能会被替换成基于 HTTP/2 的 gRPC 协议,前提是 Prometheus 和远程存储之间的所有通信都支持 HTTP/2。
配置文件
想知道如何在 Prometheus 中添加远程存储的配置,请参考前面的章节:配置远程写 和 配置远程读。
关于请求与响应消息的详细信息,可以查看远程存储相关协议的 proto 文件:
syntax = "proto3";
package prometheus;
option go_package = "prompb";
import "types.proto";
import "gogoproto/gogo.proto";
message WriteRequest {
repeated prometheus.TimeSeries timeseries = 1 [(gogoproto.nullable) = false];
}
message ReadRequest {
repeated Query queries = 1;
}
message ReadResponse {
// In same order as the request's queries.
repeated QueryResult results = 1;
}
message Query {
int64 start_timestamp_ms = 1;
int64 end_timestamp_ms = 2;
repeated prometheus.LabelMatcher matchers = 3;
prometheus.ReadHints hints = 4;
}
message QueryResult {
// Samples within a time series must be ordered by time.
repeated prometheus.TimeSeries timeseries = 1;
}
支持的远程存储
目前 Prometheus 社区也提供了部分对于第三方数据库的 Remote Storage 支持:
| 存储服务 | 支持模式 |
|---|---|
| AppOptics | write |
| Chronix | write |
| Cortex | read/write |
| CrateDB | read/write |
| Elasticsearch | write |
| Gnocchi | write |
| Graphite | write |
| InfluxDB | read/write |
| IRONdb | read/write |
| Kafka | write |
| M3DB | read/write |
| OpenTSDB | write |
| PostgreSQL/TimescaleDB | read/write |
| SignalFx | write |
| Splunk | write |
| TiKV | read/write |
| VictoriaMetrics | write |
| Wavefront | write |
联邦集群
联邦使得一个 Prometheus 服务器可以从另一个 Prometheus 服务器提取选定的时序。
使用场景
Prometheus 联邦有不同的使用场景。通常,联邦被用来实现可扩展的 Prometheus 监控设置,或者将相关的指标从一个服务的 Prometheus 拉取到另一个 Prometheus 中。
分层联邦
分层联邦允许 Prometheus 能够扩展到十几个数据中心和上百万的节点。在此场景下,联邦拓扑类似一个树形拓扑结构,上层的 Prometheus 服务器从大量的下层 Prometheus 服务器中收集和汇聚的时序数据。
例如,一个联邦设置可能由多个数据中心中的 Prometheus 服务器和一套全局 Prometheus 服务器组成。每个数据中心中部署的 Prometheus 服务器负责收集本区域内细粒度的数据(实例级别),全局 Prometheus 服务器从这些下层 Prometheus 服务器中收集和汇聚数据(任务级别),并存储聚合后的数据。这样就提供了一个聚合的全局视角和详细的本地视角。
跨服务联邦
在跨服务联邦中,一个服务的 Prometheus 服务器被配置来提取来自其他服务的 Prometheus 服务器的指定的数据,以便在一个 Prometheus 服务器中对两个数据集启用告警和查询。
例如,一个运行多种服务的集群调度器可以暴露在集群上运行的服务实例的资源使用信息(例如内存和 CPU 使用率)。另一方面,运行在集群上的服务只需要暴露指定应用程序级别的服务指标。通常,这两种指标集分别被不同的 Prometheus 服务器抓取。利用联邦,监控服务级别指标的 Prometheus 服务器也可以从集群中 Prometheus 服务器拉取其特定服务的集群资源使用率指标,以便可以在该 Prometheus 服务器中使用这两组指标集。
配置联邦
在 Prometheus 服务器中,/federate 节点允许获取服务中被选中的时间序列集合的值。至少一个 match[] URL 参数必须被指定为要暴露的序列。每个 match[] 变量需要被指定为一个不变的维度选择器像 up 或者 {job="api-server"}。如果有多个 match[] 参数,则所有符合的时序数据的集合都会被选择。
从一个 Prometheus 服务器联邦指标到另一个 Prometheus 服务器,配置你的目标 Prometheus 服务器从源服务器的 /federate 节点抓取指标数据,同时也使用 honor_lables 抓取选项(不重写源 Prometheus 服务暴露的标签)并且传递需要的 match[] 参数。例如,下面的 scrape_configs 联邦 source-prometheus-{1,2,3}:9090 三台 Prometheus 服务器,上层 Prometheus 抓取并汇总他们暴露的任何带 job="prometheus" 标签的序列或名称以 job: 开头的指标。
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
Monitor App
MSSQL
-
监控Mssql应用
在一台安装了Docker的服务器上运行mssql-exporter
export MSSQL_PASS='xxx'
sudo docker run -e SERVER=db-dev-ms01.example.com -e USERNAME=starlightdba -e PASSWORD=$DEV_MSSQL_PASS -e DEBUG=app --rm -d -p 4000:4000 --name dev-mssql awaragi/prometheus-mssql-exporter
注意:Mssql账号需要有管理员权限。
prometheus.yaml新增监控 的配置
- 监控Mssql服务器